Pinned
Unified Explanation Regarding the Issue of Unable to Invoke Tools
The primary reason tools cannot be invoked is that the model you're using isn't included in https://models.dev. You can search to see if your model exists. If it does exist, there might be an issue with the recorded capabilities for that model, indicating it doesn't support tool invocation. Alternatively, the model itself may inherently lack tool invocation capabilities, such as models in the Deepseek series. The current workaround is to locate the corresponding model within its Provider on the Settings page and manually enable its Tool Calling capability:

yetone 6 months ago
Feature Request
Pinned
Unified Explanation Regarding the Issue of Unable to Invoke Tools
The primary reason tools cannot be invoked is that the model you're using isn't included in https://models.dev. You can search to see if your model exists. If it does exist, there might be an issue with the recorded capabilities for that model, indicating it doesn't support tool invocation. Alternatively, the model itself may inherently lack tool invocation capabilities, such as models in the Deepseek series. The current workaround is to locate the corresponding model within its Provider on the Settings page and manually enable its Tool Calling capability:
yetone 6 months ago
Feature Request
不能修改默认推理强度吗
找了半天没找到,配置了optional{ "anthropic": { "thinking": { "type": "enabled", "budgetTokens": 16000 }, "effort": "max" } }就可以了吗,前端左下角还是推理强度还是默认显示中等

安静永动机 about 24 hours ago
Feature Request
不能修改默认推理强度吗
找了半天没找到,配置了optional{ "anthropic": { "thinking": { "type": "enabled", "budgetTokens": 16000 }, "effort": "max" } }就可以了吗,前端左下角还是推理强度还是默认显示中等
安静永动机 about 24 hours ago
Feature Request


Windows 下从 8.1.0 升级到 8.1.1 后,Claude CLI 订阅模式无法检测 Claude Code,并混入工具调用记录
描述: 我在 Windows 上使用 Alma 的 Claude Subscription / Claude CLI 模式时遇到问题。这个问题是在从 8.1.0 升级到 8.1.1 后开始出现的,8.1.0 版本没有遇到这个问题。 问题 1: Alma 显示 “Claude CLI not found”,但实际上 Claude Code 已经通过 npm 全局安装,并且命令行里可以正常运行。 环境: 系统:Windows Alma 版本:8.1.1 上一个正常版本:8.1.0 Claude Code 路径:C:\Users\22965\AppData\Roaming\npm\claude.exe claude --version 输出:2.1.161 (Claude Code) 可能原因: Alma 的 Claude CLI 检测逻辑似乎调用了 which claude。 但 Windows 默认没有 which 命令,Windows 下应该使用 where claude,或使用支持 PATHEXT 的跨平台可执行文件查找方式。 问题 2: 绕过检测问题后,Claude Subscription 模式的回复里会出现工具调用/历史消息内容,例如: Human: [tool result] {"stdout":"...","stderr":"","exitCode":0,"cwd":"..."} AssistantHuman: 这些内容看起来是内部工具调用结果或历史消息转换时产生的,不应该出现在最终回复里。 期望行为: Windows 下应该能正确检测到已安装的 Claude Code。 工具调用结果不应该以 [tool result]、stdout、stderr、exitCode 等原始文本形式混入 Claude 的上下文或最终回复。 空的 Human: / Assistant: 前缀也不应该出现在回复中。 可能修复方向: Windows 下使用 where claude,或使用跨平台命令查找逻辑。 在 Claude CLI 历史消息转换时,跳过 tool 类型消息,或者用结构化方式传递工具结果,避免把工具 JSON 当成普通聊天文本拼进 prompt。

Lateautumns 5 days ago
Feature Request
Windows 下从 8.1.0 升级到 8.1.1 后,Claude CLI 订阅模式无法检测 Claude Code,并混入工具调用记录
描述: 我在 Windows 上使用 Alma 的 Claude Subscription / Claude CLI 模式时遇到问题。这个问题是在从 8.1.0 升级到 8.1.1 后开始出现的,8.1.0 版本没有遇到这个问题。 问题 1: Alma 显示 “Claude CLI not found”,但实际上 Claude Code 已经通过 npm 全局安装,并且命令行里可以正常运行。 环境: 系统:Windows Alma 版本:8.1.1 上一个正常版本:8.1.0 Claude Code 路径:C:\Users\22965\AppData\Roaming\npm\claude.exe claude --version 输出:2.1.161 (Claude Code) 可能原因: Alma 的 Claude CLI 检测逻辑似乎调用了 which claude。 但 Windows 默认没有 which 命令,Windows 下应该使用 where claude,或使用支持 PATHEXT 的跨平台可执行文件查找方式。 问题 2: 绕过检测问题后,Claude Subscription 模式的回复里会出现工具调用/历史消息内容,例如: Human: [tool result] {"stdout":"...","stderr":"","exitCode":0,"cwd":"..."} AssistantHuman: 这些内容看起来是内部工具调用结果或历史消息转换时产生的,不应该出现在最终回复里。 期望行为: Windows 下应该能正确检测到已安装的 Claude Code。 工具调用结果不应该以 [tool result]、stdout、stderr、exitCode 等原始文本形式混入 Claude 的上下文或最终回复。 空的 Human: / Assistant: 前缀也不应该出现在回复中。 可能修复方向: Windows 下使用 where claude,或使用跨平台命令查找逻辑。 在 Claude CLI 历史消息转换时,跳过 tool 类型消息,或者用结构化方式传递工具结果,避免把工具 JSON 当成普通聊天文本拼进 prompt。
Lateautumns 5 days ago
Feature Request
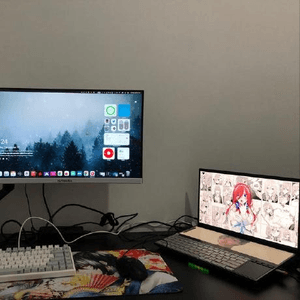
Bug: 工具调用文件链接与文本中文件路径重复渲染
当 AI 调用 Edit 工具修改文件后,聊天界面中同一文件路径会出现两次可点击的链接卡片。 **现象** 1. 工具调用输出自动生成文件路径卡片 2. AI 文本回复中提到同一文件路径时,渲染器再次生成链接卡片 **根因** 渲染层将文本中的路径链接化时,没有检查该路径是否已在当前消息的工具输出中以卡片形式存在。 **预期行为** 渲染层应去重:当前消息中工具调用已涉及的文件路径,文本中不应再被链接化。 **影响** - 同一信息出现两次,降低信息密度 - AI 侧无法根治(只能靠行为纪律避免,但必要时文本中提文件名是合理的上下文) **环境** Alma 0.0.798 macOS (Apple Silicon) 每次调用 Edit 工具后在回复中提及文件名即可复现。

Gong Cheng 6 days ago
Feature Request
Bug: 工具调用文件链接与文本中文件路径重复渲染
当 AI 调用 Edit 工具修改文件后,聊天界面中同一文件路径会出现两次可点击的链接卡片。 **现象** 1. 工具调用输出自动生成文件路径卡片 2. AI 文本回复中提到同一文件路径时,渲染器再次生成链接卡片 **根因** 渲染层将文本中的路径链接化时,没有检查该路径是否已在当前消息的工具输出中以卡片形式存在。 **预期行为** 渲染层应去重:当前消息中工具调用已涉及的文件路径,文本中不应再被链接化。 **影响** - 同一信息出现两次,降低信息密度 - AI 侧无法根治(只能靠行为纪律避免,但必要时文本中提文件名是合理的上下文) **环境** Alma 0.0.798 macOS (Apple Silicon) 每次调用 Edit 工具后在回复中提及文件名即可复现。
Gong Cheng 6 days ago
Feature Request
Activity Recorder 窗口不显示
问题: 设置中 Activity Recorder 点击后,窗口只有三个操作按钮,窗口是透明的. 电脑配置: macmini m4 15.6.1 (24G90) alma版本: 0.0.813(记不得多久了,好像最近的几个版本都有问题,最开始有这个功能的时候是正常的)

lucacici 7 days ago
Feature Request
Activity Recorder 窗口不显示
问题: 设置中 Activity Recorder 点击后,窗口只有三个操作按钮,窗口是透明的. 电脑配置: macmini m4 15.6.1 (24G90) alma版本: 0.0.813(记不得多久了,好像最近的几个版本都有问题,最开始有这个功能的时候是正常的)
lucacici 7 days ago
Feature Request
LLM Routing
Hi, I'd love to suggest a feature that could significantly reduce API costs while maintaining response quality: **intelligent query routing**. **The idea:** Before sending a request to the main LLM, a lightweight local model (e.g., a small classifier or a tiny model like Phi-3-mini / Qwen2.5-0.5B running via Ollama) evaluates the complexity of the user's query and routes it to the appropriate model: - **Simple** → fast, cheap model (e.g., Claude Haiku, GPT-4o-mini) - **Medium** → balanced model (e.g., Claude Sonnet, GPT-4o) - **Complex** → powerful model (e.g., Claude Opus, o1) **Why this matters:** In practice, 60–70% of everyday queries are simple or medium complexity. Routing them to cheaper models could cut API costs by 40–60% with little to no quality loss. There's even an open-source framework for this — [RouteLLM by Berkeley](https://github.com/lm-sys/RouteLLM) — that validates this approach. **Suggested implementation:** 1. A local routing layer that classifies each query before it's sent out 2. Three configurable tiers (Simple / Medium / Complex), each mapped to a user-selected model 3. An optional override — users can manually force a specific model for a request 4. A routing log or indicator showing which model was used and why This would be especially valuable for power users who send a high volume of mixed queries daily. It turns the app into a cost-aware assistant, not just a model wrapper. Would love to hear your thoughts on feasibility. Happy to elaborate or test a prototype if helpful! Thanks for building such a great tool.

Koben Alex 8 days ago
Feature Request
LLM Routing
Hi, I'd love to suggest a feature that could significantly reduce API costs while maintaining response quality: **intelligent query routing**. **The idea:** Before sending a request to the main LLM, a lightweight local model (e.g., a small classifier or a tiny model like Phi-3-mini / Qwen2.5-0.5B running via Ollama) evaluates the complexity of the user's query and routes it to the appropriate model: - **Simple** → fast, cheap model (e.g., Claude Haiku, GPT-4o-mini) - **Medium** → balanced model (e.g., Claude Sonnet, GPT-4o) - **Complex** → powerful model (e.g., Claude Opus, o1) **Why this matters:** In practice, 60–70% of everyday queries are simple or medium complexity. Routing them to cheaper models could cut API costs by 40–60% with little to no quality loss. There's even an open-source framework for this — [RouteLLM by Berkeley](https://github.com/lm-sys/RouteLLM) — that validates this approach. **Suggested implementation:** 1. A local routing layer that classifies each query before it's sent out 2. Three configurable tiers (Simple / Medium / Complex), each mapped to a user-selected model 3. An optional override — users can manually force a specific model for a request 4. A routing log or indicator showing which model was used and why This would be especially valuable for power users who send a high volume of mixed queries daily. It turns the app into a cost-aware assistant, not just a model wrapper. Would love to hear your thoughts on feasibility. Happy to elaborate or test a prototype if helpful! Thanks for building such a great tool.
Koben Alex 8 days ago
Feature Request
image generation fails with gpt-image-2: Unknown parameter 'response_format'
Description Image generation fails when using the openai/gpt-image-2 model with the following error: Image generation failed: Unknown parameter: 'response_format' The error occurs because the image generation code passes a response_format parameter to the OpenAI API that is not supported by the gpt-image-2 model. Steps to Reproduce Set image generation model to openai/gpt-image-2 Send a message that triggers image generation (e.g. "generate an image of ...") Image generation fails with the error above Expected Behavior Image generation should work with gpt-image-2 without passing unsupported parameters. Root Cause The gpt-image-2 model (newer OpenAI image API) does not accept the response_format parameter. This parameter was used by older models like dall-e-3 (values: url or b64_json), but the newer model API schema differs. The image generation implementation likely hardcodes or defaults response_format in the API request body, causing the request to be rejected. Suggested Fix Omit response_format when the selected model is gpt-image-2 (or any model that doesn't support it) Alternatively, detect the model family and only include supported parameters Environment Alma version: v0.0.810 Model: openai/gpt-image-2 Platform: macOS (ARM64)

hh0592821 9 days ago
Feature Request
image generation fails with gpt-image-2: Unknown parameter 'response_format'
Description Image generation fails when using the openai/gpt-image-2 model with the following error: Image generation failed: Unknown parameter: 'response_format' The error occurs because the image generation code passes a response_format parameter to the OpenAI API that is not supported by the gpt-image-2 model. Steps to Reproduce Set image generation model to openai/gpt-image-2 Send a message that triggers image generation (e.g. "generate an image of ...") Image generation fails with the error above Expected Behavior Image generation should work with gpt-image-2 without passing unsupported parameters. Root Cause The gpt-image-2 model (newer OpenAI image API) does not accept the response_format parameter. This parameter was used by older models like dall-e-3 (values: url or b64_json), but the newer model API schema differs. The image generation implementation likely hardcodes or defaults response_format in the API request body, causing the request to be rejected. Suggested Fix Omit response_format when the selected model is gpt-image-2 (or any model that doesn't support it) Alternatively, detect the model family and only include supported parameters Environment Alma version: v0.0.810 Model: openai/gpt-image-2 Platform: macOS (ARM64)
hh0592821 9 days ago
Feature Request


Custom provider `providerOptions` should be transparently passed to API request body
## Problem When using a custom-type provider (e.g. ZenMux) with `zenmux/auto` model routing, the `model_routing_config` parameter is required in the `/chat/completions` request body, but Alma's `providerOptions` mechanism does not transparently pass custom parameters to the API request. After setting `providerOptions` on a model via the API (`PUT /api/providers/:id`), the parameters never reach the actual HTTP request sent to the provider. ## Root Cause (from reverse-engineering `app.asar`) In the main process, for `custom` type providers, Alma correctly maps `providerOptions` into the AI SDK's metadata: ```js // Custom → OpenAI mapping const o = "custom" === n ? "openai" : n; Et[o] = { ...Et[o] || {}, ...e }; // e = model's providerOptions ``` However, the `@ai-sdk/openai-compatible` SDK's `getArgs` filters providerOptions through its schema: ```js Object.fromEntries( Object.entries(providerOptions?.[this.providerOptionsName] ?? {}) .filter(([key]) => !Object.keys(schema).includes(key)) ) ``` This suggests the parameters **should** pass through (unknown keys are kept), but in practice they don't reach the request body. ## Use Case ZenMux's intelligent model routing requires `model_routing_config` in the request body: ```json { "model": "zenmux/auto", "model_routing_config": { "available_models": ["sapiens-ai/agnes-2.0-flash", "google/gemini-3.5-flash", "deepseek/deepseek-v4-pro", "openai/gpt-5.4"], "preference": "balanced" } } ``` Without this parameter, the API returns: `Parameter model_routing_config is required when model is zenmux/auto`. ## Suggested Solutions - **Option A (Fix)**: Ensure `providerOptions` set on a model are transparently spread into the chat completions request body for custom-type providers - **Option B (New feature)**: Add an `extraBody` or `bodyTemplate` field to `StoredProviderModel` that gets merged into the API request body, independent of the providerOptions mechanism - **Option C (Workaround)**: Allow setting fixed body parameters at the provider level that are always included in requests ## Environment - Alma version: v0.0.810 - Provider type: custom (ZenMux) - Model: zenmux/auto
hh0592821 9 days ago
Feature Request
Custom provider `providerOptions` should be transparently passed to API request body
## Problem When using a custom-type provider (e.g. ZenMux) with `zenmux/auto` model routing, the `model_routing_config` parameter is required in the `/chat/completions` request body, but Alma's `providerOptions` mechanism does not transparently pass custom parameters to the API request. After setting `providerOptions` on a model via the API (`PUT /api/providers/:id`), the parameters never reach the actual HTTP request sent to the provider. ## Root Cause (from reverse-engineering `app.asar`) In the main process, for `custom` type providers, Alma correctly maps `providerOptions` into the AI SDK's metadata: ```js // Custom → OpenAI mapping const o = "custom" === n ? "openai" : n; Et[o] = { ...Et[o] || {}, ...e }; // e = model's providerOptions ``` However, the `@ai-sdk/openai-compatible` SDK's `getArgs` filters providerOptions through its schema: ```js Object.fromEntries( Object.entries(providerOptions?.[this.providerOptionsName] ?? {}) .filter(([key]) => !Object.keys(schema).includes(key)) ) ``` This suggests the parameters **should** pass through (unknown keys are kept), but in practice they don't reach the request body. ## Use Case ZenMux's intelligent model routing requires `model_routing_config` in the request body: ```json { "model": "zenmux/auto", "model_routing_config": { "available_models": ["sapiens-ai/agnes-2.0-flash", "google/gemini-3.5-flash", "deepseek/deepseek-v4-pro", "openai/gpt-5.4"], "preference": "balanced" } } ``` Without this parameter, the API returns: `Parameter model_routing_config is required when model is zenmux/auto`. ## Suggested Solutions - **Option A (Fix)**: Ensure `providerOptions` set on a model are transparently spread into the chat completions request body for custom-type providers - **Option B (New feature)**: Add an `extraBody` or `bodyTemplate` field to `StoredProviderModel` that gets merged into the API request body, independent of the providerOptions mechanism - **Option C (Workaround)**: Allow setting fixed body parameters at the provider level that are always included in requests ## Environment - Alma version: v0.0.810 - Provider type: custom (ZenMux) - Model: zenmux/auto
hh0592821 9 days ago
Feature Request


sleep and wake does'nt work when run long time backend task
I said: please continue and do NOT check progress constantly. But it’s not sleep / wake up correctly, It’s keep runing and burned a lot of token. ——————— here is output ———————— 思考了 488.849 秒 Wake up 716 ms Command alma wake Output Alma is awake now! Allow Once 思考了 488.849 秒 Set awake emotion 1.3 s Command alma emotion set-base awake 4 5 "woke up to restart model12 generation" Output Base emotion set: awake (energy: 4, valence: 5) Allow Once 思考了 488.849 秒 嗯... 电池没电断了。先看看上次跑了多少: Check what was generated before power loss 3.7 s Command echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== work dirs ===" && ls /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work/ 2>/dev/null | head -10 && echo "=== raw dirs ===" && ls /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw/ 2>/dev/null | head -10 Output === detections === 5 === features === 307 === work dirs === 260521-got-100 bujiyeqiu001 bujiyeqiu0022 fcc-self-001 feiren-train-002 Show 8 more lines... Allow Once 思考了 488.849 秒 5 个视频已经跑完了(307 个特征样本),续跑剩下的 22 个: Restart generation with resume 2.3 s Command cd /Users/mongo/ml-workspace/hoopx-projects/aicourt && nohup bash -c 'PYTHONPATH=src uv run python -u scripts/generate_model8_fusion_dataset.py /Users/mongo/ml-workspace/hoopx-projects/revo-video-v47 --output-dir data/model12_fusion_raw --work-dir data/model12_fusion_work --yolo-device mps' > /tmp/model12_generate.log 2>&1 & echo "PID=$!" Output PID=28423 Allow Once 思考了 488.849 秒 重跑了,续着来。先睡 5 分钟: Sleep before checking 874 ms Command alma sleep Output Alma is now sleeping. She will be grumpy if disturbed. Allow Once 思考了 488.849 秒 Sleep 5 minutes then wake 61 s Command sleep 300 && alma wake Result { "bash_id": "a65949ab-21ab-4a05-85b2-b2330f6c5942", "command": "sleep 300 && alma wake", "description": "[auto-promoted to background after 60s]", "background": true, "startedAt": "2026-05-26T11:49:34.057Z" } Allow Once 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 1.0 s 思考了 488.849 秒 TaskOutput a65949ab Completed 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 803 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 588 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 526 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 493 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 398 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 1.1 s 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 368 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 464 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 523 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 507 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 520 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 446 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 520 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 415 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 526 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 464 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 581 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 754 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 21 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 340 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 316 ms 思考了 488.849 秒 算了,5 分钟早过了,直接看进度: Check generation progress after 5 min 2.8 s Command echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== last 5 log lines ===" && tail -5 /tmp/model12_generate.log 2>/dev/null && echo "=== process ===" && pgrep -f "generate_model8" | head -2 Output === detections === 5 === features === 307 === last 5 log lines === INFO Opened video fullgame-chapter01.mp4 (960x640, 85006 frames, 60.0 fps) crop=160,40+800x600 INFO YOLO warmup completed in 0.08s (device=mps, iterations=3) INFO Rim pre-calibrated for fullgame-chapter01.mp4: source=hoop center=(0.529,0.544) diameter=0.203 samples=15 scanned=15 INFO Opened video fullgame-chapter01.mp4 (960x640, 85006 frames, 60.0 fps) crop=160,40+800x600 INFO YOLO warmup completed in 0.08s (device=mps, iterations=3) Show 4 more lines... Allow Once 思考了 488.849 秒 在跑第 6 个视频 fullgame-chapter01(85006 帧 60fps,巨长)。等 5 分钟再看: Sleep 5 min then check generation 63 s Command alma sleep && sleep 300 && alma wake && echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== last log ===" && tail -3 /tmp/model12_generate.log 2>/dev/null Result { "bash_id": "0c3a17b8-1002-412b-8ca1-e09865da0375", "command": "alma sleep && sleep 300 && alma wake && echo \"=== detections ===\" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name \"detections.json\" 2>/dev/null | wc -l && echo \"=== features ===\" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name \"*_features.json\" 2>/dev/null | wc -l && echo \"=== last log ===\" && tail -3 /tmp/model12_generate.log 2>/dev/null", "description": "[auto-promoted to background after 60s]", "background": true, "startedAt": "2026-05-26T11:51:43.898Z" } Allow Once 思考了 488.849 秒 TaskOutput 0c3a17b8 Completed 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 324 ms 思考了 488.849 秒 zzz... 等 5 分钟... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 529 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 571 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 533 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 521 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 490 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 531 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 673 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 353 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 576 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 575 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 579 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 526 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 540 ms 思考了 488.849 秒 不管了,直接查: Wake up and check generation progress 2.4 s Command alma wake 2>/dev/null; echo "=== detections: $(find data/model12_fusion_work -name 'detections.json' | wc -l) ===" && echo "=== features: $(find data/model12_fusion_raw -name '*_features.json' | wc -l) ===" && echo "=== last log ===" && tail -3 /tmp/model12_generate.log && echo "=== process ===" && pgrep -f generate_model8 | head -2 Output Alma is awake now!

Airy Linus 17 days ago
Feature Request
sleep and wake does'nt work when run long time backend task
I said: please continue and do NOT check progress constantly. But it’s not sleep / wake up correctly, It’s keep runing and burned a lot of token. ——————— here is output ———————— 思考了 488.849 秒 Wake up 716 ms Command alma wake Output Alma is awake now! Allow Once 思考了 488.849 秒 Set awake emotion 1.3 s Command alma emotion set-base awake 4 5 "woke up to restart model12 generation" Output Base emotion set: awake (energy: 4, valence: 5) Allow Once 思考了 488.849 秒 嗯... 电池没电断了。先看看上次跑了多少: Check what was generated before power loss 3.7 s Command echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== work dirs ===" && ls /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work/ 2>/dev/null | head -10 && echo "=== raw dirs ===" && ls /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw/ 2>/dev/null | head -10 Output === detections === 5 === features === 307 === work dirs === 260521-got-100 bujiyeqiu001 bujiyeqiu0022 fcc-self-001 feiren-train-002 Show 8 more lines... Allow Once 思考了 488.849 秒 5 个视频已经跑完了(307 个特征样本),续跑剩下的 22 个: Restart generation with resume 2.3 s Command cd /Users/mongo/ml-workspace/hoopx-projects/aicourt && nohup bash -c 'PYTHONPATH=src uv run python -u scripts/generate_model8_fusion_dataset.py /Users/mongo/ml-workspace/hoopx-projects/revo-video-v47 --output-dir data/model12_fusion_raw --work-dir data/model12_fusion_work --yolo-device mps' > /tmp/model12_generate.log 2>&1 & echo "PID=$!" Output PID=28423 Allow Once 思考了 488.849 秒 重跑了,续着来。先睡 5 分钟: Sleep before checking 874 ms Command alma sleep Output Alma is now sleeping. She will be grumpy if disturbed. Allow Once 思考了 488.849 秒 Sleep 5 minutes then wake 61 s Command sleep 300 && alma wake Result { "bash_id": "a65949ab-21ab-4a05-85b2-b2330f6c5942", "command": "sleep 300 && alma wake", "description": "[auto-promoted to background after 60s]", "background": true, "startedAt": "2026-05-26T11:49:34.057Z" } Allow Once 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 1.0 s 思考了 488.849 秒 TaskOutput a65949ab Completed 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 803 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 588 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 526 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 493 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 398 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 1.1 s 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 368 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 464 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 523 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 507 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 520 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 446 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 520 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 415 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 526 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 464 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 581 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 754 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 21 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 340 ms 思考了 488.849 秒 BashOutputa65949ab-21ab-4a05-85b2-b2330f6c5942 316 ms 思考了 488.849 秒 算了,5 分钟早过了,直接看进度: Check generation progress after 5 min 2.8 s Command echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== last 5 log lines ===" && tail -5 /tmp/model12_generate.log 2>/dev/null && echo "=== process ===" && pgrep -f "generate_model8" | head -2 Output === detections === 5 === features === 307 === last 5 log lines === INFO Opened video fullgame-chapter01.mp4 (960x640, 85006 frames, 60.0 fps) crop=160,40+800x600 INFO YOLO warmup completed in 0.08s (device=mps, iterations=3) INFO Rim pre-calibrated for fullgame-chapter01.mp4: source=hoop center=(0.529,0.544) diameter=0.203 samples=15 scanned=15 INFO Opened video fullgame-chapter01.mp4 (960x640, 85006 frames, 60.0 fps) crop=160,40+800x600 INFO YOLO warmup completed in 0.08s (device=mps, iterations=3) Show 4 more lines... Allow Once 思考了 488.849 秒 在跑第 6 个视频 fullgame-chapter01(85006 帧 60fps,巨长)。等 5 分钟再看: Sleep 5 min then check generation 63 s Command alma sleep && sleep 300 && alma wake && echo "=== detections ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name "detections.json" 2>/dev/null | wc -l && echo "=== features ===" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name "*_features.json" 2>/dev/null | wc -l && echo "=== last log ===" && tail -3 /tmp/model12_generate.log 2>/dev/null Result { "bash_id": "0c3a17b8-1002-412b-8ca1-e09865da0375", "command": "alma sleep && sleep 300 && alma wake && echo \"=== detections ===\" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_work -type f -name \"detections.json\" 2>/dev/null | wc -l && echo \"=== features ===\" && find /Users/mongo/ml-workspace/hoopx-projects/aicourt/data/model12_fusion_raw -type f -name \"*_features.json\" 2>/dev/null | wc -l && echo \"=== last log ===\" && tail -3 /tmp/model12_generate.log 2>/dev/null", "description": "[auto-promoted to background after 60s]", "background": true, "startedAt": "2026-05-26T11:51:43.898Z" } Allow Once 思考了 488.849 秒 TaskOutput 0c3a17b8 Completed 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 324 ms 思考了 488.849 秒 zzz... 等 5 分钟... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 529 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 571 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 533 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 521 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 490 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 531 ms 思考了 488.849 秒 ... BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 673 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 353 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 576 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 575 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 579 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 526 ms 思考了 488.849 秒 BashOutput0c3a17b8-1002-412b-8ca1-e09865da0375 540 ms 思考了 488.849 秒 不管了,直接查: Wake up and check generation progress 2.4 s Command alma wake 2>/dev/null; echo "=== detections: $(find data/model12_fusion_work -name 'detections.json' | wc -l) ===" && echo "=== features: $(find data/model12_fusion_raw -name '*_features.json' | wc -l) ===" && echo "=== last log ===" && tail -3 /tmp/model12_generate.log && echo "=== process ===" && pgrep -f generate_model8 | head -2 Output Alma is awake now!
Airy Linus 17 days ago
Feature Request
Title: .gitignore: app appends duplicate `.alma-snapshots` entry without checking existing patterns
Alma unconditionally appends.alma-snapshots to.gitignore every time it runs, without checking whether a matching pattern (e.g. **/.alma-snapshots/) already exists in the file. This results in duplicate entries and a perpetually dirty git status. Steps to reproduce: 1. Add **/.alma-snapshots/ (or any glob that already covers the path) to your .gitignore 2. Open/run Alma 3. Alma appends.alma-snapshots again at the end of the file 4. git diff now shows a new line added Expected: Alma should check if an existing pattern already matches.alma-snapshots before appending. A simple substring or line-by-line check would be sufficient. Workaround: Remove the original pattern and let Alma manage its own.alma-snapshots entry. Alma version: 0.0.790, macOS

Royce 18 days ago
Bug Reports
Title: .gitignore: app appends duplicate `.alma-snapshots` entry without checking existing patterns
Alma unconditionally appends.alma-snapshots to.gitignore every time it runs, without checking whether a matching pattern (e.g. **/.alma-snapshots/) already exists in the file. This results in duplicate entries and a perpetually dirty git status. Steps to reproduce: 1. Add **/.alma-snapshots/ (or any glob that already covers the path) to your .gitignore 2. Open/run Alma 3. Alma appends.alma-snapshots again at the end of the file 4. git diff now shows a new line added Expected: Alma should check if an existing pattern already matches.alma-snapshots before appending. A simple substring or line-by-line check would be sufficient. Workaround: Remove the original pattern and let Alma manage its own.alma-snapshots entry. Alma version: 0.0.790, macOS
Royce 18 days ago
Bug Reports
deepseek provider 是否可以自定义 base_url? 或者怎么修改自定义的 reasoning effort
我现在用 deepseek-v4- 模型也是通过自定义 provider 调用的,因为需要用自己的代理进行中间的转换统计等等。 但是发现使用自定义 provider 时,好像无法修改 reasoning_effort? 不管是 /v1/chat/completions 还是 /v1/messages。 在界面上不管选择什么 reasong effort,后端都收不到相关字段,修改 Provider Options (JSON) 貌似也没用,不会透传过来。 这种自定义的 provider 以及模型是不支持 reasong effort 吗? 或者 deepseek provider 如果可以支持自定义 base url 的话,针对 deepseek 的模型,应该也可以

afon 18 days ago
Feature Request
deepseek provider 是否可以自定义 base_url? 或者怎么修改自定义的 reasoning effort
我现在用 deepseek-v4- 模型也是通过自定义 provider 调用的,因为需要用自己的代理进行中间的转换统计等等。 但是发现使用自定义 provider 时,好像无法修改 reasoning_effort? 不管是 /v1/chat/completions 还是 /v1/messages。 在界面上不管选择什么 reasong effort,后端都收不到相关字段,修改 Provider Options (JSON) 貌似也没用,不会透传过来。 这种自定义的 provider 以及模型是不支持 reasong effort 吗? 或者 deepseek provider 如果可以支持自定义 base url 的话,针对 deepseek 的模型,应该也可以
afon 18 days ago
Feature Request

自定义 provider (opencode) 请求 kimi 模型报 cache_control 400 错误
使用自定义 provider(type: custom,apiFormat: openai-chat),走 opencode 链路(https://opencode.ai/zen/go/v1),调用 kimi-k2.6 模型时报错: AI_APICallError: Error from provider: 2 request validation errors: Extra inputs are not permitted, field: 'messages[0].cache_control'; Extra inputs are not permitted, field: 'messages[1].cache_control' 复现步骤: 添加 custom provider,baseURL 为 https://opencode.ai/zen/go/v1 apiFormat 设为 openai-chat 选择该 provider 下的 kimi-k2.6 模型发消息 每次请求必现 400 根因分析: Alma 在构造消息请求时,给所有 provider 的消息体里加了 Anthropic 专有的 cache_control 字段(prompt caching 标记),但没有按 apiFormat 做字段过滤。对于 openai-chat 格式的 provider,应该剥离 cache_control,但目前被原样发送了。OpenCode 网关严格校验 OpenAI 格式,直接拒绝。 同类案例(供参考): OpenOmniBot #301:同问题,修复方式是 buildOpenAICompatibleRequestBody() 中递归清除 cache_control earendil-works/pi #3779:同样走 opencode 链路,同样 cache_control 报 400,修复方式是给非 Anthropic 模型加 compat 标记 环境: Alma 版本:127 Provider 类型:custom,apiFormat: openai-chat 目标模型:kimi-k2.6(via opencode)

钱军 20 days ago
Bug Reports
自定义 provider (opencode) 请求 kimi 模型报 cache_control 400 错误
使用自定义 provider(type: custom,apiFormat: openai-chat),走 opencode 链路(https://opencode.ai/zen/go/v1),调用 kimi-k2.6 模型时报错: AI_APICallError: Error from provider: 2 request validation errors: Extra inputs are not permitted, field: 'messages[0].cache_control'; Extra inputs are not permitted, field: 'messages[1].cache_control' 复现步骤: 添加 custom provider,baseURL 为 https://opencode.ai/zen/go/v1 apiFormat 设为 openai-chat 选择该 provider 下的 kimi-k2.6 模型发消息 每次请求必现 400 根因分析: Alma 在构造消息请求时,给所有 provider 的消息体里加了 Anthropic 专有的 cache_control 字段(prompt caching 标记),但没有按 apiFormat 做字段过滤。对于 openai-chat 格式的 provider,应该剥离 cache_control,但目前被原样发送了。OpenCode 网关严格校验 OpenAI 格式,直接拒绝。 同类案例(供参考): OpenOmniBot #301:同问题,修复方式是 buildOpenAICompatibleRequestBody() 中递归清除 cache_control earendil-works/pi #3779:同样走 opencode 链路,同样 cache_control 报 400,修复方式是给非 Anthropic 模型加 compat 标记 环境: Alma 版本:127 Provider 类型:custom,apiFormat: openai-chat 目标模型:kimi-k2.6(via opencode)
钱军 20 days ago
Bug Reports
